Un programme en BASIC qui ferait un listing de lui-même. Reprogrammer l'instruction LIST. C'est un peu inutile, mais cela est un prétexte pour expliquer comment le programme est stocké en mémoire dans la machine.
Le VG5000µ utilise une version du BASIC-80 de Microsoft. Ce BASIC se retrouve sur d'autres machines dans des versions variées, mais dont on retrouve les grands principes.
Structure générale d'un programme en mémoire
Comme on l'a vu précédemment, le BASIC respecte un pointeur vers le début du programme qui se nomme (txttab), situé en $488E. Par défaut avec la ROM interne du VG5000µ, si aucune extension ne l'a modifié, (txttab) vaut $49FC au démarrage.
Chaque ligne est composée par les éléments suivants :
- Une adresse mémoire (sur 2 octets) vers l'emplacement de la ligne suivante, ou
$0000pour marquer la fin de la liste de lignes, - Un numéro de ligne (sur 2 octets) qui correspond au numéro de ligne BASIC,
- Un ensemble d'octets représentant le contenu de la ligne, qui se termine pas un
$00
Juste après le zéro se trouve la nouvelle ligne, et la ROM maintient les lignes dans l'ordre de leur numéro de ligne BASIC.
L'ensemble des lignes stockées forme donc une « liste chaînée » selon le schéma suivant.
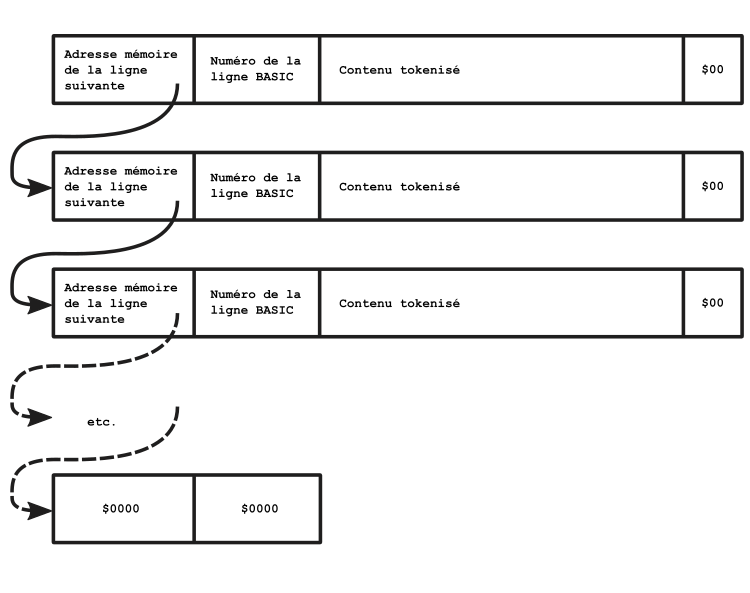
Note : comme la dernière ligne est suivi par le pointeur vers l'adresse $0000, le BASIC en profite pour gagner un octet et ne met pas spécifiquement un $00 à la fin de cette ligne, puisqu'il y en a déjà 4.
Pour notre programme de décodage de ce qui se trouve dans la mémoire, il va donc falloir d'abord aller récupérer l'adresse de (txttab). On pourrait la mettre en dur, mais faisons ça proprement.
Le BASIC sur VG5000µ n'a comme instruction pour lire la mémoire que PEEK, qui ne lit qu'un octet. Qu'à cela ne tienne, voici une petite fonction qui, donnée une variable P pointant sur une zone mémoire, en retourne la valeur entière sur 16 bits qui y est stockée.
DEFFNPK(P)=PEEK(P+1)*256+PEEK(P)
De là, on peut donc partir de (txttab) puis de parcourir tout le chaînage jusqu'à trouver un pointeur nul ($0000).
Ce qui peut donner ça :
10020 DEFFNPK(P)=PEEK(P+1)*256+PEEK(P) : REM Définition de la fonction pour lire un entier sur 2 octets
10030 PT=FNPK(&"488E") : REM Récupération de (txttab)
10040 NX=FNPK(PT) : REM Lecture du pointeur **next** (ligne suivante)
10050 IF NX=0 THEN 10200 : REM Si ce pointeur est nul, on sort plus loin
10060 PT=PT+2:LI=FNPK(PT) : REM Sinon, on avant le pointeur de 2 et on lit le numéro de ligne
10070 PRINT LI;" "; : REM On affiche le numéro de ligne
10080 PT=PT+2:GOSUB 1300 : REM On avance le pointeur de 2 et on décode la ligne (voir plus loin)
10090 PT=NX : REM Passage du pointeur vers la ligne suivante
10100 GOTO 10040 : REM Et on boucle...
Voici le corps principal du programme écrit. Avec ça, même en ne mettant qu'un RETURN en ligne 1300, vous pouvez voir les numéros de ligne du votre programme s'afficher.
Décodage du contenu des lignes
Les lignes sont formées d'une suite d'octets terminée par un $00, située entre le numéro de la ligne BASIC et l'adresse de début de la ligne suivante.
Le contenu d'une ligne peut contenir des caractères, mais aussi des tokens. Les tokens (jetons en français) représentent les instructions, fonctions et signes reconnus par le BASIC lorsque la ligne a été analysée à l'entrée par le clavier (sur cassette, les tokens sont enregistrés, et donc chargés, directement).
Un token est facilement reconnaissable, son bit de poids fort est à 1. Autrement dit, si le caractère présent est strictmeent supérieur à 127, il s'agit d'un token. D'ailleurs, lorsque l'on entre un programme au clavier, le BASIC fait bien attention de mettre tous les caractères entrés sur 7 bits.
C'est aussi dans ce traitement que le BASIC va chercher, à l'aide d'une liste de mots-clés et signes connus, à reconnaître et donc de tokeniser la ligne. Dès qu'une suite de caractères est un mot-clé ou un signe connu, la suite de caractères est remplacée, dans la chaîne encodée, par son token.
Si les caractères lus ne forment pas un mot connu, ceux-ci sont copiés tels quels dans la ligne encodée.
Par exemple, si BASIC encode la ligne : PRINT"HELLO", le résultat sera la suite $94,'"', 'H','E,'L','L','O','"',$00.
Le décodage
Pour reconstituer la ligne, il s'agit donc de prendre les caractères un par un et de vérifier. Est-ce un token ou pas ? Si ce n'est pas un token, on l'écrit directement à l'écran (ou presque, on va voir plus loin). Si c'est un token, on soustrait 128 à sa valeur pour avoir son index.
Les tokens
Reste à retrouver le token dans la table située en $209E et donc un extrait à partir du début ressemble à cela :
defb $c5,$4e,$44,$c6,$4f,$52,$ce,$45,$58,$54 ; .ND.OR.EXT
defb $c4,$41,$54,$41,$c9,$4e,$50,$55,$54,$c4 ; .ATA.NPUT.
defb $49,$4d,$d2,$45,$41,$44,$cc,$45,$54,$c7 ; IM.EAD.ET.
defb $4f,$54,$4f,$d2,$55,$4e,$c9,$46,$d2,$45 ; OTO.UN.F.E
defb $53,$54,$4f,$52,$45,$c7,$4f,$53,$55,$42 ; STORE.OSUB
defb $d2,$45,$54,$55,$52,$4e,$d2,$45,$4d,$d3 ; .ETURN.EM.
defb $54,$4f,$50,$cf,$4e,$cc,$50,$52,$49,$4e ; TOP.N.PRIN
defb $54,$c4,$45,$46,$d0,$4f,$4b,$45,$d0,$52 ; T.EF.OKE.R
defb $49,$4e,$54,$c3,$4f,$4e,$54,$cc,$49,$53 ; INT.ONT.IS
defb $54,$cc,$4c,$49,$53,$54,$c3,$4c,$45,$41 ; T.LIST.LEA
...
Cette table est encodée de la manière suivante : les mots-clés sont les uns à la suite des autres. Chaque premier caractère a son bit de poids fort à 1, ce qui marque la séparation entre les mots.
Faisons un essai : $94 est le token pour PRINT, soit 148 en décimal. 148 - 128 = 20. Mais attention, le premier token est 128, donc il faut commencer à compter à partir de 0. Cherchez le 21ième mot clé et vous lirez .RINT (attention, le .PRINT précédent est le codage de LPRINT)
Pour faire plus simple, vous pouvez aussi compter 21 points.
Dans mon premier essai de programme, j'avais traduit en BASIC ce que fait la ROM en assembleur : à chaque mot-clé, on parcours la table des mots-clés depuis le début. À chaque fois que l'on rencontre un caractère supérieur ou égal a 128, on décroit le numéro du token d'une unité. Arrivé à zéro, on a trouvé, on peut donc recopier à l'écran tous les caractères (sur 7 bits) jusqu'au prochain supérieur ou égal à 128, exclu.
Ça fonctionne. Mais ce qui est très rapide en assembleur demande beaucoup de manipulations au BASIC. Parcourir un long tableau et faire des comparaisons et des tests est très lourd, même en usant de quelques astuces.
Lorsqu'il fallait décoder un token élevé, comme le signe = (token 65) ou la fonction MID$ (token 95, le dernier), le décodage devenait très long, très très long.
J'ai donc finalement opté pour payer le coût de décodage une fois, au détriment d'une consommation mémoire plus importante.
5000 PRINT"INITIALISATION..." : REM Affichage d'un message, parce que c'est un peu long
5010 DIM K(95) : REM Il y 96 tokens, de 0 à 95
5020 KT=&"209E" : REM Adresse du début de la table
5030 KW=0 : REM Initialisation avec le Keyword 0
5040 K(KW)=KT:KW=KW+1 : REM Adresse du Keyword courant dans le tableau et augmentation de l'index
5050 KT=KT+1 : REM Déplacement à l'adresse suivante de la table
5060 IF PEEK(KT) AND 128 THEN 5080 : REM Si bit de poids fort, on saute
5070 GOTO 5050 : REM Sinon, on boucle sur l'avancée dans la table
5080 IF (PEEK(KT) AND 127) = 0 THEN RETURN : REM Si la caractère est $80, c'est fini !
5090 GOTO 5040 : REM Sinon, on boucle sur l'enregistrement de l'adresse
Note : j'aurai pu écrire ça avec une boucle FOR car pour cette ROM là, je connais la taille de la table, qui ne bougera pas, mais je voulais garder ce bout de code flexible. Il fonctionnera pour une autre tableau d'un autre BASIC-80.
Décoder le token revient maintenant à aller chercher son adresse dans la table puis de recopier les caractères jusqu'au premier marquant le début du mot suivant.
1500 REM KT <- ADRESSE TOKEN(V)
1510 KW=V-128 : REM Calcul du token à partir du caractère lu
1520 KT=K(KW) : REM Lecture de l'adresse de son nom en mémoire
1530 REM PRINT(KEYWORD(KT))
1540 R$="":C=PEEK(KT) : REM Préparation de la chaîne et lecture du premier caractère
1550 R$=R$+CHR$(C AND 127) : REM Construction de la chaîne
1560 KT=KT+1 : REM Passage à l'adresse suivante
1570 C=PEEK(KT) : REM Lecture du caractère suivant
1580 IF C>127 THEN 1600 : REM Si c'est le mot suivant, on saute plus loin
1590 GOTO 1550 : REM SInon, on boucle sur la construction
1600 PRINT R$;:RETURN : REM Le mot est trouvé, on l'affiche et on revient à l'appelant
Note : j'aurai pu afficher directement chaque caractère plutôt que de construire la chaîne au fur et à mesure. Je n'ai pas vérifié ce qui serait le plus rapide. Cette version là use pas mal la mémoire de chaînes de caractère, c'est certain.
Les entiers compactés
Je n'ai aucune idée de si c'est leur nom officiel, mais c'est comme celui que je les appelle. Certains nombres sont encodées par le BASIC dans une forme particulière : le caractère $0E suivi d'un nombre entier codé sur 16 bits (donc deux octets).
En particulier, les numéros de lignes sont codées de cette manière. Ainsi les instructions de saut comme GOTO ou GOSUB n'ont pas à décoder systématiquement le numéro en paramètre. Il a déjà été décodé et stocké dans la ligne.
Afficher un entier compacté n'est pas très compliqué grâce à la fonction de lecture d'un entier sur 16 bits.
2999 REM PRINT(NUM16(I+1))
3000 I=I+1 : REM I pointe vers le caractère $0E, l'entier est juste après
3010 PRINT(FNPK(I));":";
3020 I=I+2 : REM On saute les deux caractères lus
3030 RETURN
Note : lorsque le BASIC utilise un entier compacté, il induit aussi une fin d'instruction. Il n'encode donc pas le séparateur ':' éventuel. Je l'affiche donc ici systématiquement, ce qui n'est pas tout à fait correct car il apparaît parfois en fin de ligne. Ce n'est pas syntaxiquement faux non plus.
Les différents cas
Il y a donc trois cas pour un caractère à décoder, auquel j'ajoute une quatrième :
- Si le caractère est un
token, on le décode, - Sinon, si le caractère est
$0E, on décode un entier compacté, - Sinon, s'il est inférieur à 17 ou égal à 30 et 31, c'est un caractère de contrôle, on le remplace par le caractère espace,
- Sinon, on le recopie tel quel.
Ce qui donne :
1300 REM DECODE LA LIGNE ENTRE PT ET NX
1310 FOR I=PT TO NX-1 : REM Décodage sur tout le contenu (voir la note juste après)
1320 V=PEEK(I) : REM Lecture du caractère
1330 IF V AND 128 THEN GOSUB 1500:GOTO 1370 : REM Est-ce un token ?
1340 IF V=14 THEN GOSUB 3000:GOTO 1370 : REM Est-ce un entier comptacté ?
1350 IF V<17 OR V=30 OR V=31 THEN V=32 : REM Est-ce un caractère non affichable ?
1360 PRINT CHR$(V); : REM Affichage du caractère
1370 NEXT I : REM Fin de la boucle
1380 PRINT : REM Saut à la ligne quand c'est terminé
1390 RETURN
Note : la ROM ne fait pas tout à fait comme ça, elle décode jusqu'à trouver le $00. Dans la pratique, les lignes sont stockées dans l'ordre du chaînage, par ordre de ligne croissant. Je décode donc entre le début du contenu de la chaîne tokenisé et la ligne suivante.
Conclusion
Voilà donc réunies toutes les pièces qui permettent de lister le programme en mémoire... et donc le programme lui-même.
L'instruction LIST incluse dans la ROM du VG5000µ est meilleure que cela : les commentaires sont affichés d'une couleur différente, il n'y a pas d'espace avant les numéros de lignes, pas de ':' qui traînent derrière les GOTO et GOSUB en fin de ligne.
Mais l'idée était surtout de montrer comment était encodé le listing en mémoire.
Et pour finir, le programme en entier.
10 GOTO 10000
1300 REM DECODE LA LIGNE ENTRE PT ET NX
1310 FOR I=PT TO NX-1
1320 V=PEEK(I)
1330 IF V AND 128 THEN GOSUB 1500:GOTO 1370
1340 IF V=14 THEN GOSUB 3000:GOTO 1370
1350 IF V<17 OR V=30 OR V=31 THEN V=32
1360 PRINT CHR$(V);
1370 NEXT I
1380 PRINT
1390 RETURN
1500 REM KT <- ADRESSE TOKEN(V)
1510 KW=V-128
1520 KT=K(KW)
1530 REM PRINT(KEYWORD(KT))
1540 R$="":C=PEEK(KT)
1550 R$=R$+CHR$(C AND 127)
1560 KT=KT+1
1570 C=PEEK(KT)
1580 IF C>127 THEN 1600
1590 GOTO 1550
1600 PRINT R$;:RETURN
2999 REM PRINT(NUM16(I+1))
3000 I=I+1
3010 PRINT(FNPK(I));":";
3020 I=I+2
3030 RETURN
5000 PRINT"INITIALISATION..."
5010 DIM K(94)
5020 KT=&"209E"
5030 KW=0
5040 K(KW)=KT:KW=KW+1
5050 KT=KT+1
5060 IF PEEK(KT) AND 128 THEN 5080
5070 GOTO 5050
5080 IF (PEEK(KT) AND 127) = 0 THEN RETURN
5090 GOTO 5040
10000 REM DEMARRAGE
10010 GOSUB 5000
10020 DEFFNPK(P)=PEEK(P+1)*256+PEEK(P)
10030 PT=FNPK(&"488E")
10040 NX=FNPK(PT)
10050 IF NX=0 THEN 10200
10060 PT=PT+2:LI=FNPK(PT)
10070 PRINT LI;" ";
10080 PT=PT+2:GOSUB 1300
10090 PT=NX
10100 GOTO 10040
10200 PRINT"FINI"
11000 END